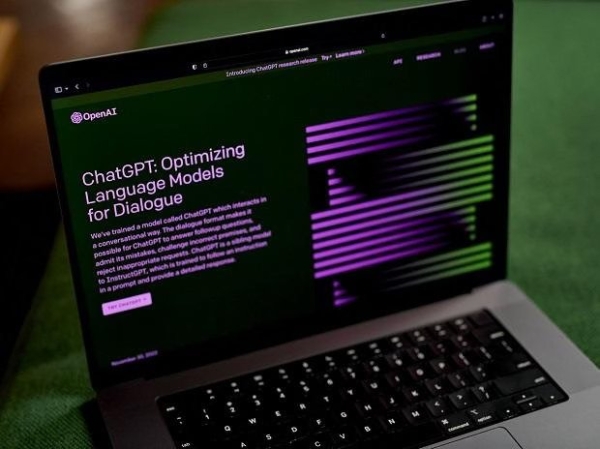
Microsoft-backed OpenAI announces GPT-4 large language model: Details here
In a blog post on Tuesday, OpenAI wrote, "We have created GPT-4, the next milestone in our attempts to expand deep learning."We spent 6 months iteratively align
- by B2B Desk 2023-03-15 05:20:10
OpenAI, owned by Microsoft, has announced its new large media model GPT-4 that accepts image and text input.
In a blog post on Tuesday, OpenAI wrote, "We have created GPT-4, the next milestone in our attempts to expand deep learning.
"We spent 6 months iteratively aligning GPT-4 using lessons from our adversarial test software, as well as ChatGPT, resulting in the best results with respect to factuality, steerability, and refusal to break the barrier."
Compared to GPT-3.5, the new AI model is more reliable, more creative, and capable of handling complex instructions.
GPT-4 outperforms existing extensive language models (LLMs), including more modern models (SOTA), which may include additional standards-specific constructs or training methods.
The company claimed that GPT-4 outperformed GPT-3.5 English and other LLMs (Chinchilla, PaLM) in 24 out of the 26 examined languages, including low-resource languages like Latvian, Welsh, and Swahili.
The company is also using this new model internally, with a significant impact on functions like support, sales, content modification, and scheduling.
Unlike a text-only setup, this form can accept a claim with text and images, allowing users to define any language or vision task.
The GPT-4 base model, like previous GPT models, was taught to predict the next word in a document. It was trained using authoritative and publicly available data.
ChatGPT Plus subscribers will get access to GPT-4 at chat.openai.com with a usage limit, while developers can subscribe to the GPT-4 API queue.
"We expect GPT-4 to become a valuable tool in improving people's lives by powering a multitude of applications," the company said.
Also Read: Koo launches new feature to enable creators to compose posts using ChatGPT

POPULAR POSTS
What Is LLM Visibility? A Simple Guide to Checking Your AI Visibility
by Aakash Ladha , 2026-07-15 11:44:33
OpenAI Launches GPT-Live: Making Conversations with ChatGPT Feel Truly Human
by Aayush Ladha, 2026-07-14 12:28:52
Otobot Technologies: Driving the Future of Automotive Innovation
by Aayush Ladha, 2026-07-06 12:06:39
Speakers United Concludes Its Biggest Debate Camp Yet 80 Students, Zero AI Assistance
by Aayush Ladha, 2026-07-01 11:26:25
The Agentic Revolution: Why Salesforce Is Betting Its Future on AI Agents
by Shan, 2025-11-05 10:29:23
OpenAI Offers ChatGPT Go Free in India: What’s Behind This Big AI Giveaway?
by Shan, 2025-10-28 12:19:11
Zoho Products: Complete List, Launch Years, and What Each One Does
by Shan, 2025-10-13 12:11:43
Follow on Insta
RECENTLY PUBLISHED

How Praveen Gowdru Went From Building VMEDO To Launching Tez Health And Why He Betting On Home Healthcare
- by Aakash Ladha , 2026-07-01 11:01:27

How a Kerala Startup is Using Robots to Clean Sewers and Manholes
- by Aakash Ladha , 2026-07-14 12:14:26

Luxemettle Redefining Indias Jewellery Market With Personalized Craftsmanship and Story Driven Design
- by Aakash Ladha , 2026-07-14 12:07:23


x
![logo]()
